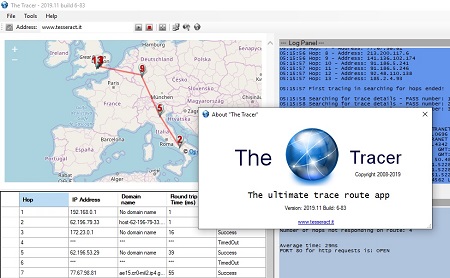
 Abbiamo appena rilasciato una nuova versione dell’applicativo The Tracer, il nostro tool di diagnostica di rete.
Abbiamo appena rilasciato una nuova versione dell’applicativo The Tracer, il nostro tool di diagnostica di rete.
Il software è completamene gratuito e disponibile all’indirizzo:
http://www.tesseract.it/TheTracer/
Enjoy.
Abbiamo appena rilasciato una nuova versione dell’applicativo The Tracer, il nostro tool di diagnostica di rete.
Il software è completamene gratuito e disponibile all’indirizzo:
http://www.tesseract.it/TheTracer/
Enjoy.
Gli artisti possono colorare il cielo di rosso perché sanno che è blu. Quelli di noi che non sono artisti devono colorare le cose come realmente sono o la gente penserebbe che sono stupidi.
Jules Feiffer
La console testuale, la nostra fidata cmd.exe o il nostro terminale Linux o macOS, sono notoriamente dei mondi spartani e minimalisti. Tuttavia, anche in questi contesti un tocco di colore può aiutare a rendere l’output maggiormente intuitivo e piacevole da gestire. Il problema è che per realizzare anche il più piccolo inserimento di colori, utilizzando il nostro codice C, dobbiamo faticare non poco a causa della eterogeneità dei vari sistemi operativi e ambienti di sviluppo.
Un primo approccio che possiamo provare a sfruttare è quello di pilotare il nostro terminale attraverso specifiche sequenze di comandi note come sequenze di escape. Più precisamente, si tratta di uno standard ANSI (ovvero dell’American National Standards Institute) che consente di inviare al terminale una serie di comandi, di norma utilizzando il carattere Esc seguito dalla parentesi quadra ‘[‘, con i quali controllare non solo i colori ma anche la posizione del cursore sullo schermo. Storicamente, si tratta di uno stratagemma molto datato che fu introdotto addirittura a partire dagli anni 70 e particolarmente 80 del secolo scorso per sostituire il vecchio metodo che consisteva nell’utilizzare comandi legati all’hardware dei singoli e specifici dispositivi. Nonostante siano passati moltissimi anni, questo metodo è ancora utilizzabile con una certa efficienza grazie al fatto che è possibile inviare comandi al terminale utilizzando caratteri ASCII standard.

Figura 1 – Il terminale VT 100 della Digital (https://commons.wikimedia.org/wiki/File:DEC_VT100_terminal.jpg).
Può essere interessante sapere che uno dei primi e più popolari terminali a supportare questo nuovo standard fu il VT100 della Digital. Personalmente, lo ricordo ancora con un po’ di malinconia in quanto questo fu il primo terminale con il quale mi imbattei all’Università degli Studi di Salerno nella seconda metà degli anni 80.
Il primo problema che riscontriamo con l’utilizzo delle sequenze di escape è che esse sono supportate in maniera pressoché nativa solo in ambiente Unix like e non sotto Windows. Cominciamo comunque a verificarne il loro utilizzo almeno sotto il contesto Linux per prendere confidenza con questo strumento.
Un primo stralcio di codice minimale con il quale fare una veloce prova può essere il seguente:
#include <stdio.h>
int main ()
{
printf("\x1b[32mUn mondo a colori\n");
}
Come si intuisce il contenuto da analizzare è il seguente:
"\x1b[32mUn mondo a colori\n"
In tale contenuto riconosciamo facilmente che prima della stringa “Un mondo a colori” è presente una arcana sequenza di simboli:
"\x1b[32m"
Ebbene, in realtà non è nulla di particolarmente complesso. Infatti, come già detto, le sequenze di escape iniziano con il codice del carattere Esc seguito da una parentesi quadra aperta. Tale carattere di escape corrisponde al valore decimale 27 che, in esadecimale, corrisponde a 1b ed è proprio tale valore che inviamo al terminale usando la sequenza di due simboli “\x”.
In successione troviamo il valore 32 che corrisponde al colore verde e infine la lettera m che serve a segnalare al terminale che stiamo inviando un comando di gestione di tipo grafico.
Se compiliamo il file sotto Windows e proviamo a lanciarlo nella console cmd.exe otterremo un deludente risultato simile a quanto riportato in figura:
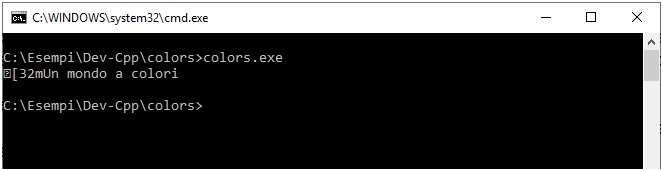
Figura 2 – L’esecuzione con l’invio dei codici di escape con la cmd.exe.
Come si può osservare, in output troviamo in maniera grezza parte della sequenza inviata senza però nessuna modifica di colore. Al contrario, se lanciamo lo stesso eseguibile in un contesto Unix like, ad esempio nella finestra Bash del sottosistema Windows per Linux (configurabile sotto Windows 10) otterremo la corretta interpretazione del comando grafico, così come mostrato in figura:
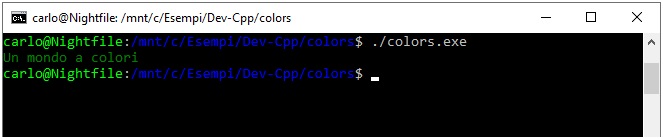
Figura 3 – L’esecuzione con l’invio dei codici di escape nel sottosistema Windows per Linux.
La cosa interessante da notare è che una volta impartito un certo comando di impostazione di un dato colore, tale setting rimane invariato finché non decidiamo di inviare il codice per un colore diverso oppure per resettare il sistema al bianco e nero inviando il valore zero. Di seguito, vi riporto del codice che dovrebbe chiarire il meccanismo in questione:
#include <stdio.h>
int main ()
{
printf("\x1b[32mUn mondo a colori\n");
printf("... tutto verde\n");
printf("\x1b[0m");
printf("ma fino a un certo punto.\n");
}
In output otterremo, come mostrato in Figura, che le prime due righe risulteranno in verde mentre la riga di testo finale, “ma fino a un certo punto.”, verrà mostrata in bianco su nero a causa del comando di reset:
"\x1b[0m"
dove riconosciamo ancora la sequenza \x1b che invia in esadecimale in carattere Esc, poi la parentesi quadra aperta e quindi il valore zero per il reset seguito dalla lettera m che segnala, come già detto, l’invio di un comando di tipo grafico.
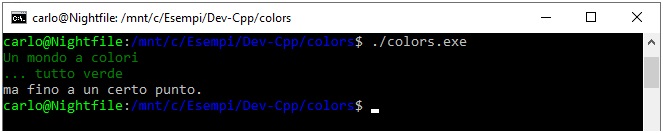
Figura 4 – L’esecuzione con l’invio dei codici per il reset delle impostazioni di colore predefinite.
Vediamo ora di scoprire l’elenco dei colori che possiamo gestire. Ebbene, i colori di base solo sostanzialmente solo otto ed i loro codici vanno da 30 a 37. Tuttavia, gli stessi otto colori possono essere utilizzati per cambiare il colore di sfondo della console con dei codici che vanno da 40 a 47. Di seguito vi propongo uno schema riassuntivo.
| COLORE | CODICE TESTO | CODICE SFONDO |
| Nero | 30 | 40 |
| Rosso | 31 | 41 |
| Verde | 32 | 42 |
| Giallo | 33 | 43 |
| Blu | 34 | 44 |
| Magenta | 35 | 45 |
| Azzurro | 36 | 46 |
| Bianco | 37 | 47 |
Ovviamente, volendo cambiare contemporaneamente il colore del testo e quello dello sfondo dobbiamo inviare due specifici e differenti comandi. Ad esempio, volendo impostare il testo nero su sfondo bianco dovremo inviare, rispettivamente, i valori 30 e 47. Di seguito un semplice esempio:
#include <stdio.h>
int main ()
{
printf("\x1b[30m");
printf("\x1b[47m");
printf("Un mondo al contrario.\n");
printf("\x1b[0m");
}
Incidentalmente, vi faccio notare come sarebbe possibile inserire i due comandi in un’unica stringa di testo accodando le due sequenze di escape scrivendo:
printf("\x1b[30m\x1b[47m");
Appurato che gli ambienti di derivazione Unix gestiscono senza problemi le sequenze di escape vediamo ora cosa ci riserva il mondo Windows. Purtroppo la possibilità di usare in maniera quasi naturale tali sequenze è limitata alle sole versioni di Windows 10.
NOTA. Vedi anche https://docs.microsoft.com/en-us/windows/console/console-virtual-terminal-sequences.
Vediamo allora un programmino minimale che imposta l’ambiente al fine di utilizzare le sequenze in questione:
#include <stdio.h>
#include <windows.h>
#ifndef ENABLE_VIRTUAL_TERMINAL_PROCESSING
#define ENABLE_VIRTUAL_TERMINAL_PROCESSING 0x0004
#endif
int main()
{
//Catturo l'handle del dispositivo standard di output
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE);
//uso tale handle per ottenere l'attuale modalità della console
DWORD dwMode = GetConsoleMode(hOut, &dwMode);
//Abilito le sequenze di escape mettendo in OR alla modalità corrente
//del buffer dello schermo della console il valore ENABLE_VIRTUAL_TERMINAL_PROCESSING
dwMode = dwMode | ENABLE_VIRTUAL_TERMINAL_PROCESSING;
//Imposto la nuova modalità con la funzione SetConsoleMode
SetConsoleMode(hOut, dwMode);
printf("\x1b[32mUn mondo a colori\n");
printf("... tutto verde\n");
printf("\x1b[0m");
printf("ma fino a un certo punto.\n");
return 0;
}
Come detto, l’esecuzione di tale codice su sistemi antecedenti ad un aggiornato Windows 10 fallirà miseramente.
Proviamo allora ad analizzare il codice in questione partendo dalla necessità di definire la costante ENABLE_VIRTUAL_TERMINAL_PROCESSING. Usiamo quindi le cosiddette include guard #ifndef per evitare la eventuale redefinizione della costante in questione che viene richiesta dal sistema per poter gestire in maniera corretta le sequenze di escape.
Per il resto, il commento nel codice dovrebbe essere sufficiente a comprendere il meccanismo di funzionamento del sistema in questione. Quello che facciamo è innanzitutto prelevare il riferimento (noto come handle) del dispositivo di output, ovvero della console, con l’istruzione:
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE);
Usiamo allora questo handle per poter leggere l’attuale impostazione della console:
DWORD dwMode = GetConsoleMode(hOut, &dwMode);
Incidentalmente, segnalo che un dword, abbreviazione di “double word,” è un tipo di dati specifico di Windows. Tale tipo è definito nel file windows.h che abbiamo incluso in testa al nostro codice. Un dword è un intero senza segno a 32 bit e può quindi contenere un valore che va da 0 a 4.294.967.295.
Successivamente, aggiungiamo, tramite l’operatore OR la nuova impostazione al contesto corrente, usando la funzione SetConsoleMode:
dwMode = dwMode | ENABLE_VIRTUAL_TERMINAL_PROCESSING; SetConsoleMode(hOut, dwMode);
A questo punto, il gioco è fatto e possiamo inviare le sequenze di escape di nostro interesse verso il dispositivo console.
Ovviamente, per rendere il codice più robusto dovremmo preoccuparci di controllare con apposito trapping di errore se le operazioni richieste vanno a buon fine. A tal fine, vi segnalo come si possa usare la funzione GetLastError() per catturare l’eventuale errore generato dalle varie chiamate viste in precedenza. Per essere più chiaro, vi propongo la riscrittura del codice precedente con l’inserimento di vari check per testare se le operazioni richieste vanno o meno a buon fine.
#include <stdio.h>
#include <windows.h>
#ifndef ENABLE_VIRTUAL_TERMINAL_PROCESSING
#define ENABLE_VIRTUAL_TERMINAL_PROCESSING 0x0004
#endif
int main()
{
//Catturo l'handle del dispositivo standard di output
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE);
if (hOut == INVALID_HANDLE_VALUE)
{
printf("Funzione GetStdHandle - Errore: %d\n", GetLastError());
}
//uso tale handle per ottenere l'attuale modalità della console
DWORD dwMode = 0;
if (!GetConsoleMode(hOut, &dwMode))
{
printf("Funzione GetConsoleMode - Errore: %d\n", GetLastError());
}
//Abilito le sequenze di escape mettendo in OR alla modalità corrente
//del buffer dello schermo della console il valore ENABLE_VIRTUAL_TERMINAL_PROCESSING
dwMode = dwMode | ENABLE_VIRTUAL_TERMINAL_PROCESSING;
//Imposto la nuova modalità con la funzione SetConsoleMode
if (!SetConsoleMode(hOut, dwMode))
{
printf("Funzione SetConsoleMode - Errore: %d\n", GetLastError());
}
printf("\x1b[32mUn mondo a colori\n");
printf("... tutto verde\n");
printf("\x1b[0m");
printf("ma fino a un certo punto.\n");
return 0;
}
Come si vede, effettuiamo il controllo in relazione alla chiamate delle varie funzioni e, nel caso di effettivo errore, stampiamo con GetLastError lo specifico numero di errore. Ovviamente, per verificare sul campo tali situazioni dobbiamo porci in un contesto che generi effettivamente un errore. In figura vi mostro quello che può succedere in ambiente Windows 7 che, come detto, non consente l’uso delle sequenze di escape.
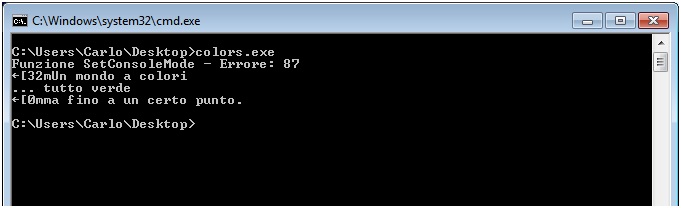
Figura 5 – La generazione e il relativo trapping di un errore con le sequenze di escape sotto Windows 7.
Come si vede dalla figura in questione, l’errore generato è il numero 87. Spulciando la documentazione Microsoft, ad esempio all’URL https://docs.microsoft.com/en-us/windows/win32/debug/system-error-codes–0-499-, si scopre che tale numero corrisponde all’errore “The parameter is incorrect.”. In ogni caso, può essere utile sapere che è possibile rendere la gestione degli errori ancora più espressiva utilizzando la funzione FormatMessage per farsi restituire la specifica stringa descrittiva dello specifico errore.
Una valida alternativa su Windows per controllare i colori della console può essere quella di sfruttare una funzione dell’API di Windows nota come SetConsoleTextAttribute. Di seguito vi mostro la sua struttura e modalità di utilizzo.
Il suo prototipo è:
BOOL SetConsoleTextAttribute( HANDLE hConsoleOutput, // handle del buffer dello schermo della console WORD wAttributes // colori per il testo e lo sfondo );
Per rendere immediatamente comprensibile il suo funzionamento vi mostro subito un semplice esempio:
#include <stdio.h>
#include <windows.h>
int main()
{
HANDLE output = GetStdHandle(STD_OUTPUT_HANDLE);
printf("Questo e' il colore di default\n");
SetConsoleTextAttribute(output, FOREGROUND_RED|FOREGROUND_INTENSITY);
printf("Il colore rosso e' proprio bello\n");
SetConsoleTextAttribute(output, FOREGROUND_BLUE|FOREGROUND_INTENSITY);
printf("ma anche il blu non e' male\n");
return 0;
}
La prima cosa che possiamo notare è l’include relativo al file windows.h. Subito dopo, con la riga:
HANDLE output = GetStdHandle(STD_OUTPUT_HANDLE);
otteniamo un handle per il buffer dello schermo. Usiamo tale handle come primo argomento della funzione SetConsoleTextAttribute mentre come secondo argomento impostiamo, in due momenti diversi, due differenti colori con le costanti FOREGROUND_RED e FOREGROUND_BLUE. Banalmente si tratta dei colori rosso e blu. Vi faccio notare come si possa accodare, con l’operatore OR, rappresentato dal simbolo “|” (noto come pipe), un ulteriore attributo rappresentato dalla costante FOREGROUND_INTENSITY. Tale costante serve per far sì che il colore appena selezionato sia visualizzato con una maggiore luminosità.
Ovviamente, i colori disponibili sono diversi. Di seguito un estratto riassuntivo:
| COLORE | TESTO | SFONDO |
| Blu | FOREGROUND_BLUE | BACKGROUND_BLUE |
| Verde | FOREGROUND_GREEN | BACKGROUND_GREEN |
| Rosso | FOREGROUND_RED | BACKGROUND_RED |
| Intensificazione del colore | FOREGROUND_INTENSITY | BACKGROUND_INTENSITY |
NOTA. Per ulteriori informazioni sui buffer della console https://docs.microsoft.com/en-us/windows/console/console-screen-buffers.
Un altro elemento interessante da analizzare è dato dal fatto che le precedenti costanti di colore possono essere combinate, con l’operatore OR, non solo con la costante per esaltare la luminosità del colore stesso ma anche con altre costanti di colore per ottenere varie e differenti combinazioni. Ad esempio, la combinazione:
BACKGROUND_BLUE | BACKGROUND_GREEN | BACKGROUND_RED
produrrà uno sfondo bianco che potrà essere esaltato in intensità accodando la costante BACKGROUND_INTENSITY e scrivendo quindi un comando del tipo:
SetConsoleTextAttribute(output, BACKGROUND_BLUE | BACKGROUND_GREEN | BACKGROUND_RED | BACKGROUND_INTENSITY);
Carlo A. Mazzone

Il concetto di oggetto informatico è assolutamente comprensibile se lo si paragona ad un oggetto del mondo reale. Non a caso, uno scopo degli oggetti della programmazione è proprio quello di simulare le proprietà e i comportamenti del mondo fisico. Un oggetto è dunque un’entità caratterizzata da una serie di caratteristiche specifiche (note come proprietà) e da un serie di possibili azioni (noti come metodi) che l’oggetto può realizzare eventualmente in risposta ad situazioni (note come eventi) che si verificano nel contesto attinente all’oggetto. Facciamo un banale esempio volendo rappresentare un oggetto per codificare i dati di una persona e vediamo come codificarlo in JavaScript.
<!DOCTYPE html>
<html>
<head>
<title>Gli oggetti di JavaScript</title>
</head>
<body>
<script>
var persona = { nome: “Carlo”, cognome: “Mazzone”, altezza: 180, capelli: “castani” };
document.write(“Io sono ” + persona.nome + ” ” + persona.cognome);
</script>
</body>
</html>
Per completezza ho riportato anche l’intero codice per una pagina HTML di esempio. Si intuisce, con grande semplicità, che la riga:
var persona = { nome: “Carlo”, cognome: “Mazzone”, altezza: 180, coloreOcchi: “castani” };
rappresenta una serie di coppie, separate da virgole, del tipo chiave:valore. ad esempio nome: “Carlo”. Quella presentata è la forma di creazione di un oggetto minimale e le coppie in questione sono le proprietà dell’oggetto. Nell’istruzione di stampa:
document.write(“Io sono ” + persona.nome + ” ” + persona.cognome);
si vede poi l’uso dell’operatore punto per accedere al valore delle varie proprietà. Faccio notare che la modalità di scrittura di un oggetto su di una singola linea è solo una possibilità e che, in generale, se ne preferisce una differente che vede ogni singola proprietà su di una specifica linea di codice come mostrato di seguito:
var persona = {
nome: “Carlo”,
cognome: “Mazzone”,
altezza: 180,
capelli: “castani”
};
Ovviamente, possiamo cambiare a piacimento il valore delle proprietà di un oggetto. Ad esempio, potremmo cambiare la proprietà nome scrivendo:
persona.nome=”Ludovica”;
Ancora, è possibile utilizzare la parola chiave new per la creazione, in un certo modo in differita dell’oggetto, scrivendo:
var persona = new Object();
persona.nome=”Carlo”;
persona.cognome=”Mazzone”;
persona.altezza=180;
persona.capelli=”castani”;
Tuttavia, in generale, si sconsiglia l’uso di questo secondo metodo, anche per una questione di velocità di esecuzione del codice, preferendo la modalità:
var persona = {
nome: “Carlo”,
cognome: “Mazzone”,
altezza: 180,
capelli: “castani”
};
Nella terminologia anglosassone questo tipo di oggetto viene definito object literal. Literal, infatti, è il modo con cui ci si riferisce ai valori assegnati alle costanti (in contrapposizione al termine variabile). In questo caso, infatti, quello che facciamo è proprio definire un oggetto con dei valori costanti preimpostati.
Sappiamo che è possibile assegnare un nuovo valore ad una proprietà scrivendo:
persona.nome=”Ludovica”;
Ebbene, sempre nell’ordine delle cose per cui è possibile realizzare le stesse operazioni in modo differente, vi segnalo che è possibile riferirsi al valore di una proprietà anche nel seguente modo:
persona[“nome”]=”Ludovica”;
Inoltre, è possibile riferirsi al nome di una proprietà di un dato oggetto passando ad esso una variabile contenente quel nome. Sembra complicato, ma si tratta di una banalità che vi mostro di seguito. Posso assegnare ad una variabile generica il nome del campo cognome in questo modo:
var temp=”cognome”;
e successivamente accedere, ad esempio per la stampa, alla corrispondente proprietà:
document.write(persona[temp]);
Faccio notare incidentalmente come sia possibile creare un oggetto vuoto attraverso la seguente sintassi:
var persona = {};
per poi andare ad inserire in esso delle proprietà, così come già visto in precedenza, scrivendo, ad esempio:
persona.nome=”Carlo”;
Inoltre, così come tali proprietà possono essere create sarà anche possibile eliminarle scrivendo, ad esempio:
delete persona.nome;
oppure:
delete persona[“nome”];
Ovviamente, una volta eliminata una specifica proprietà, andandone a stampare il valore, ad esempio con:
document.write(persona[“nome”]);
otterremmo in output un valore di tipo undefined segnalando che la proprietà in esame non è appunto definita.
Inutile dire che provare ad eliminare delle proprietà di oggetti predefiniti può essere un’idea quantomeno folle che può inevitabilmente portare a blocchi del sistema.
Finora abbiamo capito come sia possibile gestire un oggetto visto sostanzialmente come un contenitore di dati. Se ci pensiamo bene, infatti, gli oggetti appena studiati non sono altro che una sorta di array un po’ speciali in quanto possiamo inserire in essi dei valori di tipo differente (ad esempio, nell’oggetto persona abbiamo utilizzato dei valori stringa ed un numero). Tuttavia, ciò che rende un oggetto un “tipo” davvero speciale è la possibilità di gestire al proprio interno, oltre ai semplici dati (le proprietà), anche delle specifiche azioni realizzate attraverso delle funzioni che abbiamo definito con il nome di metodi. La creazione di specifici metodi all’interno di un oggetto rende quest’ultimo un’entità quasi autonoma capace di azioni proprie. Non dico che realizziamo un’entità capace di intendere e di volere ma la direzione è forse quella.
Vediamo allora come cominciare ad instillare un anelito vitale all’interno dell’oggetto inserendo in esso una funzione che gli dia la possibilità di “parlare”. Inizialmente l’oggetto si presenterà dicendo il proprio nome e cognome. Dunque, procediamo modificando l’oggetto persona come segue:
var persona = {
nome: “Carlo”,
cognome: “Mazzone”,
altezza: 180,
capelli: “castani”,
parla: function() {
document.write(“Io sono ” + persona.nome + ” ” + persona.cognome);
}
};
Per far parlare la nostra “persona” invocheremo il metodo parla scrivendo:
persona.parla();
Come è possibile osservare, quello che facciamo è di inserire, insieme alle proprietà separando normalmente i vari elementi con una virgola, una funzione che abbiamo chiamato banalmente parla. Notiamo come si debba scrivere prima il nome della funzione e poi, dopo i due punti, la parola chiave function. Si tratta di una sintassi che rende omogenea la dichiarazione delle proprietà e dei metodi. Ovviamente, bisogna fare attenzione al corretto uso delle virgole che servono per separare le varie dichiarazioni onde evitare errori durante l’esecuzione del codice.
Qualcuno potrebbe obiettare che tale modifica rispetto allo script precedente non introduce alcuna innovazione di comportamento. In effetti è così, almeno all’apparenza. Il senso è che dal punto di vista del risultato pratico i due pezzi di codice danno in output lo stesso risultato:
Io sono Carlo Mazzone
Tuttavia, essi lo realizzano in maniera, anche filosoficamente, del tutto diversa. Mentre nel primo caso l’istruzione di stampa:
document.write(“Io sono ” + persona.nome + ” ” + persona.cognome);
è esterna all’oggetto e viene quindi eseguita all’esterno dell’oggetto stesso, nel secondo caso, è l’oggetto stesso ad avere la “capacità di parola” e tutto quello che dobbiamo fare è di dirgli di usarla (si parla di “invio di messaggi all’oggetto”). Si tratta di una inversione di vedute, di un cambio assoluto di paradigma di programmazione, per cui è l’oggetto ad essere al centro del contesto di programmazione racchiudendo in esso, come in una scatola nera tutta la logica di funzionamento. Faccio notare incidentalmente che questo approccio che consiste nel nascondere all’interno di un oggetto i dettagli del codice per cui il programmatore non deve preoccuparsi del modo in cui inviare messaggi agli oggetti prende il nome, in questo paradigma, di information hiding (occultamento dell’informazione) attraverso una tecnica nota come incapsulamento.
Tutto ciò rappresenta la base per costruire moduli software che siano facilmente utilizzabili e che abbiano grande scalabilità, ovvero possano essere modificati per contenere nuove funzionalità in maniera non traumatica. Inoltre, questo approccio ad oggetti consente uno sviluppo a più mani (diversi programmatori sullo stesso progetto) in maniera più efficiente.
Per rafforzare il senso della vita interna di un oggetto vi invito ad osservare la seguente modifica all’oggetto persona:
var persona = {
nome: “Carlo”,
cognome: “Mazzone”,
altezza: 180,
capelli: “castani”,
parla: function() {
document.write(“Io sono ” + this.nome + ” ” + this.cognome);
}
};
in cui abbiamo utilizzato la parola chiave this. Tale riferimento, che banalmente ha il significato di “questo” si riferisce all’oggetto stesso e serve per generalizzare e semplificare la scrittura del codice.
Faccio ora notare come il metodo realizzato sia una procedura e non una vera e propria funzione. Infatti, esso provvede direttamente a stampare la stringa di presentazione e non restituisce nulla all’esterno. In realtà, per rendere il codice più professionale e manutenibile è necessario trasformare il metodo in una vera e propria funzione scrivendo:
var persona = {
nome: “Carlo”,
cognome: “Mazzone”,
altezza: 180,
capelli: “castani”,
parla: function() {
return(this.nome + ” ” + this.cognome);
}
};
document.write (“Io sono ” + persona.parla());
Giusto per fare una semplice considerazione rispetto alla bontà di questa soluzione di codifica alternativa possiamo pensare al fatto che in questo modo l’oggetto è maggiormente indipendente rispetto al resto del codice. In buona sostanza, abbiamo in un certo senso separato la parte di “business logic”, ovvero di funzionamento vero e proprio, rispetto alla parte di “interfaccia” realizzata con la chiamata document.write. In questo modo, giusto per intenderci, anche una possibile traduzione in altre lingue del nostro codice sarebbe più semplice in quanto realizziamo lo specifico output all’esterno dell’oggetto. Ad esempio, avremmo potuto scrivere:
document.write (“My name is ” + persona.parla());
L’oggetto persona visto in precedenza ha sicuramente grande utilità ma nasconde anche alcuni limiti. Innanzitutto, come già detto, esso è un sorta di costante. Infatti, lo abbiamo definito un object literal. Può essere utile a questo proposito spendere qualche parola in più relativamente allo sviluppo software in un senso più generale. Scrivere codice non è semplicemente l’azione consistente nel mettere una dopo l’altra una serie di righe di codice. Ogni progetto, anche il più piccolo, prevede uno specifico approccio alla sua realizzazione tramite codice. Si parla, in linea generale, di paradigmi di programmazione intendendo appunto la metodologia usata per creare uno specifico software. Infatti, indipendentemente dal fatto che si possano realizzare con un dato codice le medesime funzionalità, queste possono essere codificate in maniera sostanzialmente diversa. Seppure questo testo non sia un trattato di programmazione in senso stretto, trovo utile fornire qui alcune informazioni di base. Fondamentalmente e semplificando al massimo, un certo problema può essere risolto in due modalità principali. La prima, nota essenzialmente come approccio top-down (dall’alto verso il basso), prevede di scomporre il problema principale in tanti problemi più piccoli (noti come sottoproblemi) e per ognuno di questi scrivere una specifica funzione che risolva il particolare problema. Spesso, un dato sottoproblema è troppo complesso per essere risolto da una singola funzione e così esso viene ulteriormente scomposto in sottoproblemi e relative funzioni associate per risolverli. Per essere concreti, supponiamo di dover gestire in un nostro sito web la registrazione degli utenti tramite specifiche credenziali. Ebbene, il problema nella sua totalità può innanzitutto essere scomposto in un serie di sottoproblemi quali, ad esempio, la registrazione tramite i propri dati personali (logon) e l’accesso al sito attraverso i dati in proprio possesso (login). D’altra parte il logon prevede almeno due ulteriori sottoproblemi: il primo per la registrazione dei dati immessi dall’utente ed un secondo per la validazione, ad esempio tramite l’invio di una mail, della veridicità dei dati forniti dall’utente in questione. Come si vede, partiamo dall’alto (top) intendendo il problema nella sua totalità e andiamo verso il basso (down) scomponendo il tutto in sottoproblemi ai quali assoceremo specifiche funzioni. Questo approccio viene normalmente definito approccio procedurale: non a caso i sottoproblemi vengono gestiti attraverso specifiche procedure.
Tuttavia, oltre a questo approccio ne esiste un altro che per certi aspetti si muove in direzione opposta: si parte dal basso e si va verso l’alto. Si parla, infatti, di approccio bottom-up che si estrinseca in maniera pratica attraverso il paradigma ad oggetti. Cerchiamo allora di fare un po’ più di chiarezza. Dire che si parte dal basso (bottom) vuol dire iniziamo il nostro studio per la risoluzione del problema lavorando sui dati piuttosto che sulle procedure. Mi spiego meglio facendo riferimento all’esempio della gestione dei dati del nostro utente via web. Nell’approccio ad oggetti partiamo proprio definendo innanzitutto le caratteristiche dell’utente quali nome, cognome, password, email, ecc.. Altra caratteristica dell’utente sarà, inoltre, uno stato che definisce se l’utente è in un certo momento loggato al sistema oppure no. Ciò, infatti, condiziona le attività da realizzarsi in quanto se l’utente non risulta loggato dovremo eventualmente redirigere la sua navigazione verso la fase di login. Dunque, si definiscono le proprietà degli oggetti e anche le funzioni (i metodi) ad essi associati. Mettendo insieme le funzionalità dei vari oggetti “saliamo verso l’alto” rispettando il senso dell’approccio bottom-up.
È importante precisare che da un lato abbiamo il paradigma e dall’altro il linguaggio di programmazione. Il senso è che teoricamente con lo stesso linguaggio possiamo operare sfruttando l’uno o l’altro paradigma. Ovviamente ciò deve essere permesso dal linguaggio stesso: si parla in questo caso di linguaggi multi-paradigma. Per fare qualche esempio concreto, il linguaggio C supporta nativamente il solo paradigma procedurale mentre linguaggi come C++ o Java sono stati costruiti per essere utilizzato con lo sviluppo ad oggetti ma teoricamente possono essere usati anche con un approccio procedurale. Nel campo dello sviluppo web, sia JavaScript che PHP (che vedremo nel prosieguo del nostro viaggio) possono essere usati in entrambi i modi anche se, comunque, il suggerimento è di sfruttare le più moderne possibilità di sviluppo del paradigma ad oggetti.
Torniamo ora a parlare di oggetti da un punto di vista più tecnico. Affinché si possa parlare di programmazione orientata agli oggetti è importante che gli oggetti abbiamo alcune caratteristiche molto precise tra cui il fatto che essi possano essere creati a partire da uno specifico modello che indichi le caratteristiche comuni a tutti gli oggetti: la classe. Per classe si intende una sorta di stampo a partire dal quale creare oggetti tutti simili ma comunque singoli e unici. Può essere utile immaginare una classe come una formina che i bambini usano per giocare con la sabbia. La formina consente di creare elementi di sabbia tutti uguali ma ognuno è indipendente dagli altri avendo, ad esempio, una posizione sulla spiaggia diversa dagli altri. Di seguito un esempio di classe per l’oggetto persona visto in precedenza:
function Persona(nome, cognome, altezza, capelli) {
this.nome = nome;
this.cognome = cognome;
this.altezza = altezza;
this.capelli = capelli;
this.parla = function () {
return(this.nome + ” ” + this.cognome);
};
}
Vediamo dunque che cosa abbiamo realizzato. In buona sostanza abbiamo scritto una funzione, che viene chiamata costruttore in quanto costruisce l’oggetto. Vi faccio notare come abbia scelto come nome per la funzione il termine Persona scritto con l’iniziale in maiuscolo. Si tratta di una sorta di convenzione per indicare il fatto che abbiamo a che fare con una funzione costruttore. All’interno della funzione assegniamo i vari argomenti presi in input dalla funzione stessa (nome, cognome, altezza, capelli) a specifiche proprietà realizzate con la parola chiave this. Allo stesso modo definiamo il metodo parla, in maniera simile a quanto visto in precedenza con gli object literal. Tuttavia, una volta realizzato il costruttore dobbiamo invocare in maniera esplicita la creazione di un particolare oggetto. La creazione in questione avviene con la parola chiave new come vi mostro di seguito:
var Carlo = new Persona(“Carlo”, “Mazzone”, 180, “castani”);
dove abbiamo creato un nuovo oggetto, Carlo, con le proprietà elencate nello specifico passaggio di parametri. Ovviamente possiamo poi richiamare le specifiche proprietà:
document.write (Carlo.altezza);
e invocare i metodi di nostro interesse:
document.write (“Io sono ” + Carlo.parla());
Se ci riflettiamo un attimo, quello che abbiamo realizzato non è da poco. Siamo ora in grado di creare tutti gli oggetti di un certo tipo di cui necessitiamo: si parla di istanze della classe. Ad esempio, possiamo scrivere:
var Ciccio = new Persona(“Ciccio”, “Pasticcio”, 160, “bianchi”);
per creare un nuovo oggetto di tipo Persona che si chiama Ciccio. Ovviamente, possiamo creare un oggetto anche solo indicando alcuni parametri alla funzione costruttore:
var Topolino = new Persona(“Mickey”, “Mouse”);
Ovviamente, nel caso del nostro esempio, la stampa di una proprietà non inizializzata quale:
document.write (Topolino.altezza);
darà come risultato undefined. In ogni caso, addirittura, possiamo creare un oggetto privo di inizializzazione con:
var Topolino = new Persona();
e successivamente valorizzare i suoi membri:
Topolino.nome=”Mickey”;
Topolino.cognome=”Mouse”;
Un altro aspetto importante da sottolineare relativamente alla grande utilità di questo approccio è che, contrariamente a quanto succede con gli object literal, non siamo costretti a definire i vari metodi degli oggetti per ogni singola istanza. Infatti, definiremo le funzioni di interesse dell’oggetto una volta per tutte nel costruttore e potremo poi richiamarle dal singolo oggetto scrivendo, ad esempio:
document.write (“Io sono ” + Topolino.parla());
Gli oggetti JavaScript hanno in serbo ancora alcune sorprese. Tanto per dirne una, è possibile associare al volo una nuova proprietà ad un certo oggetto. Ad esempio, in relazione alla situazione seguente:
function Persona(nome, cognome, altezza, capelli) {
this.nome = nome;
this.cognome = cognome;
this.altezza = altezza;
this.capelli = capelli;
this.parla = function () {
return(this.nome + ” ” + this.cognome);
};
}
var Carlo = new Persona(“Carlo”, “Mazzone”, 180, “castani”);
var Ciccio = new Persona(“Ciccio”, “Pasticcio”, 160, “bianchi”);
possiamo scrivere:
Carlo.userName=”carlomazzone”;
dove abbiamo inserito la nuova proprietà userName al solo oggetto Carlo mentre l’oggetto Ciccio rimane immutato. In maniera similare, possiamo aggiungere anche un metodo ad un singolo oggetto (istanza di una classe) scrivendo, ad esempio:
Carlo.saluta = function () {
return(“Ciao, ciao da ” + this.nome);
};
Abbiamo così aggiunto la funzione saluta al solo oggetto Carlo. La cosa interessante da notare è che dentro la funzione in questione ho comunque potuto usare la parola chiave this per fare riferimento ad una proprietà interna all’oggetto.
Tuttavia, ribadisco che nuove proprietà e nuovi metodi possono essere aggiunti, con il semplice uso del carattere punto legato al nome dell’oggetto, solo in relazione alla specifica istanza e quindi al singolo oggetto. Infatti, se volessimo aggiungere determinate proprietà e metodi a tutti gli oggetti derivanti da una data classe dovremmo per forza di cose lavorare sul costruttore dell’oggetto. Vediamo allora come procedere in questo scenario. Per farlo è necessario ricorrere ad una nuova parola chiave: prototype. Usiamo dunque tale nuova keyword in un esempio concreto, sempre relativo alla classe Persona, scrivendo:
Persona.prototype.email=”info@example.com”;
Quello che abbiamo fatto è stato associare al costruttore di Persona una nuova proprietà che abbiamo chiamato email ed inizializzato al valore info@example.com. Ciò significa che tale proprietà con relativo valore è associata in automatico a tutti gli oggetti già istanziati a partire dalla classe Persona e che quindi, sempre in relazione all’esempio precedente, le seguenti istruzioni:
document.write (Carlo.email);
document.write (Ciccio.email);
restituiranno in output due volte la stringa info@example.com.
La tecnologia che si nasconde dietro ai prototipi è la base sulla quale di fonda la cosiddetta ereditarietà della programmazioni ad oggetti nel mondo di JavaScript. Tuttavia, a questo punto credo sia necessario spendere qualche ulteriore parola su questo argomento data la sua importanza in relazione allo sviluppo software che usa gli oggetti come principale paradigma di programmazione. L’ereditarietà consente di definire degli oggetti di base che possono poi essere utilizzati per costruire nuovi oggetti che dai primi prendono le proprietà e gli eventi già in essi presenti e ne aggiungono di nuovi per specializzare i propri comportamenti. In buona sostanza un modo per non riscrivere ogni volta tutto il codice ma sfruttare quanto già presente in altri oggetti. Questo meccanismo che consente di sfruttare caratteristiche di altri oggetti in una sorta di albero genealogico è appunto chiamato ereditarietà. Ogni linguaggio che usa il paradigma ad oggetti deve per forza di cosa implementare questo meccanismo ed ognuno, tuttavia, lo realizza in maniera leggermente diversa. Java, ad esempio, implementa in maniera leggermente diversa dal C++ l’ereditarietà e ancora differentemente lo fa JavaScript che, come detto, sfrutta il meccanismo dei prototipi.
 All’interno di Windows 10, la cartella C:\Program Files\ è visibile con questo nome solo accedendo tramite prompt dei comandi. Infatti, se proviamo a visualizzare la struttura di cartella tramite Esplora file, vedremo, al di sotto della radice, due cartelle simili che hanno a che fare con i programmi e la loro installazione: C:\Programmi e C:\Programmi (x86).
All’interno di Windows 10, la cartella C:\Program Files\ è visibile con questo nome solo accedendo tramite prompt dei comandi. Infatti, se proviamo a visualizzare la struttura di cartella tramite Esplora file, vedremo, al di sotto della radice, due cartelle simili che hanno a che fare con i programmi e la loro installazione: C:\Programmi e C:\Programmi (x86).
Il motivo di questa organizzazione è dato dal fatto che quello che vediamo tramite Esplora file è una localizzazione, ovvero la traduzione nella lingua del sistema operativo, ad esempio l’italiano, rispetto al nome reale delle cartelle.
In ogni caso, la cartella visibile come C:\Programmi corrisponde, come detto, alla cartella reale C:\Program Files. Tale cartella, nei sistemi a 64 bit, ormai la quasi totalità, contiene le installazioni degli applicativi, appunto a 64 bit. Invece, la cartella visibile come C:\Programmi (x86) corrisponde alla cartella reale C:\Program Files (x86) nella quale vengono installate le versioni a 32 bit dei vari programmi di cui si effettua il setup (installazione).
Le applicazioni scritte per l’ambiente a 64 bit vengono eseguite in maniera normale, tecnicamente di dice nativa, mentre quelle a 32 bit vengono emulate nell’ambito di un processo di nome WOW64 (Win32 On Win64).
Carlo A. Mazzone
 Anche se si tratta di un problema abbastanza banale, ho notato che spesso si incespica in errori dovuti alla differente natura delle istruzioni di input del C, scanf e getchar, quando queste sono accodate l’una dopo l’altra per prelevare determinati valori inseriti dall’utente. Il problema è dato dal fatto che dopo una scanf rimane nel buffer della tastiera il carattere di new line (nuova linea), ovvero, più semplicemente, la pressione del tasto “invio” stesso. Tale invio forza in automatico una “digitazione fantasma” nella eventuale successiva istruzione getchar.
Anche se si tratta di un problema abbastanza banale, ho notato che spesso si incespica in errori dovuti alla differente natura delle istruzioni di input del C, scanf e getchar, quando queste sono accodate l’una dopo l’altra per prelevare determinati valori inseriti dall’utente. Il problema è dato dal fatto che dopo una scanf rimane nel buffer della tastiera il carattere di new line (nuova linea), ovvero, più semplicemente, la pressione del tasto “invio” stesso. Tale invio forza in automatico una “digitazione fantasma” nella eventuale successiva istruzione getchar.
Il piccolo programmino di seguito dovrebbe chiarire il problema e presentare la possibile soluzione:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char argv[])
{
printf("INPUT DA ESAURIMENTO\n");
char ch1, ch2;
printf("Inserisci il primo carattere: ");
scanf("%c", &ch1);
printf("Inserisci il secondo carattere: ");
ch2 = getchar();
printf("ch1=%c, Valore ASCII = %d\n", ch1, ch1);
printf("ch2=%c, Valore ASCII = %d\n", ch2, ch2);
printf("RIPROVA, SARAI PIU' FORTUNATO ;)\n");
printf("Inserisci il primo carattere: ");
scanf("%c", &ch1);
fflush(stdin);
printf("Inserisci il secondo carattere: ");
ch2 = getchar();
printf("ch1=%c, Valore ASCII = %d\n", ch1, ch1);
printf("ch2=%c, Valore ASCII = %d\n", ch2, ch2);
return 0;
}
Come si può vedere, il codice prima simula la situazione di errore e poi ci mette una pezza. Ci sono due modi principali per farlo.
Il primo è di usare la funzione
fflush(stdin);
che provvede a svuotare il buffer in questione, subito dopo la scanf e prima della getchar. Il problema che potremmo avere con tale funzione è che essa non è propriamente standard.
L’alternativa è di usare, al suo posto, la riga di codice:
while ( getchar() != '\n' );
che cicla fino a beccare, e mandare ramengo 😉 il newline.
Per rendere ancora più interessante l’esempio stampiamo anche il codice ASCII dei caratteri inseriti. Nella prima parte dell’esecuzione si può allora toccare con mano la problematica appena illustrata osservando che il carattere ch2 ha come codice ASCII il valore 10 che corrisponde proprio al LF (Line Feed – https://it.wikipedia.org/wiki/Ritorno_a_capo) .
Carlo A. Mazzone
Dovrebbe essere notorio che per sviluppare codice non è possibile usare editor “evoluti” come Microsoft Word oppure il Writer presente il LibreOffice e OpenOffice in quanto questi salvano i file NON in formato testo semplice ma aggiungono ai contenuti tutta una serie di codici proprietari che altererebbero il sorgente della nostra software. Abbiamo quindi bisogno di editor di testo puro.
Seppure, il Blocco Note possa risultare utile in un primissimo momento di avvicinamento allo specifico linguaggio, immediatamente dopo (e sto parlando di qualche minuto se non di pochi secondi ;), è il caso di munirsi di strumenti più efficienti. L’elenco di editor di testo all’interno del quale scegliere il proprio applicativo preferito è davvero vasto. Si tratta di ottimi software, spesso gratuiti, che consentono di scrivere, ad esempio i tag HTML, con semplificazioni tipo la colorazione del codice, la possibilità di gestire più file aperti contemporaneamente e diversi altri strumenti. Di seguito suggerisco alcune possibilità.
Notepad++, scaricabile all’indirizzo http://notepad-plus-plus.org/, è un editor di testo gratuito che supporta diversi linguaggi. Come altri software del genere, esso è basato su un componente base noto come Scintilla, http://www.scintilla.org/, ed è realizzato usando il linguaggio di programmazione C++ per l’ambiente Microsoft Windows.
PSPad è un altro editor per Microsoft Windows che risulta utile in diverse circostanze in quanto, oltre alle classiche funzionalità, come la colorazione del codice o la possibilità di apertura contemporanea di diversi documenti, dispone di diversi strumenti aggiuntivi. Ad esempio, possiede un client FTP integrato che consente l’apertura e la modifica di file in remoto. Inoltre, esso incorpora un registratore di macro per registrare, memorizzare e riprodurre sequenze di operazioni ripetitive. Ancora, dispone di strumenti di selezione dei colori con la traduzione dei loro codici nelle differenti notazioni.
Un altro editor di sicuro interesse è Atom, il cui sito di riferimento è all’indirizzo atom.io. Atom è open source, multipiattaforma e quindi disponibile per OS X, Windows e Linux. Gli autori di Atom tengono a sottolineare il fatto che il software in questione sia altamente personalizzabile adattando il cosiddetto “look and feel” dell’interfaccia grafica ai propri specifici gusti.
Brackets è un’altra alternativa di sicuro interesse. Si tratta di un edito di testi open source che strizza l’occhio agli sviluppatori web. Il sito di riferimento è brackets.io.
Visual Studio Code è un editor di codice sorgente che, in qualche modo in maniera sorprendente per essere un prodotto Microsoft, è disponibile, oltre che ovviamente per Windows, anche per Mac e Linux. Il sito di riferimento è code.visualstudio.com. Esso supporta in maniera nativa i linguaggi JavaScript e TypeScript ma gestisce una serie di estensioni per altri linguaggi come, ad esempio, C++, C#, Python e PHP. Inoltre, Visual Studio Code supporta lo sviluppo con diversi runtime tra i quali Node.js e Unity.
Nel contesto informatico un archivio di dati, inteso come collezione omogenea di elementi atti a contenere informazione, è noto con il termine database, letteralmente base di dati.
Un classico e semplice esempio può essere rappresentato da un’agenda telefonica nella quale disponiamo di una serie di righe in cui inseriamo in una posizione un nominativo e nella posizione successiva il corrispondente numero telefonico:
| Nominativo | Telefono |
| Carlo Mazzone | 347/9478… |
| Pippo De Pippis | 333/1234… |
| …. | …. |
| Ciccio Pasticcio | 0824/7711… |
L’intera organizzazione è nota come tabella, le singole righe vengono normalmente chiamate record mentre le singole caselle sono note come campi. In generale le tabelle posseggono una intestazione per ogni colonna che serve ad identificare i valori in essa inseriti. Nell’esempio proposto le intestazioni sono “nominativo” e “telefono”. Tali etichette sono anche note come “nome del campo”. Una o più tabelle sono sufficienti per la definizione di un database.
Spesso si confonde un database, che è “semplicemente” l’organizzazione dei dati, con l’intera applicazione predisposta a gestire gli archivi e i loro contenuti. Tale applicazione è, più propriamente, denominata con il termine DBMS (Database Management System) ovvero sistema per la gestione di database. Per intenderci, per chi conosce l’applicativo Microsoft Access, Access stesso è un DBMS mentre i file da esso prodotti (tipicamente con estensione .mdb) sono i veri e propri database.
Incidentalmente riportiamo il nome di una figura professionale di grande importanza connessa con i DB (abbreviazione per database) e i DBMS: il DBA ovvero Database Administrator. Il DBA è colui che si occupa della gestione e manutenzione di un database e ovviamente conosce le modalità operative del DBMS. Da notare che i DBMS, anche se in determinati contesti posseggono caratteristiche organizzative e di manutenzione simili, possono essere anche molto diversi tra loro.
Sono oggi disponibili vari applicativi DBMS (Microsoft SQL Server, Oracle, MySQL, PostgreSQL, …) e in generale un DBA è costretto a specializzarsi su di uno specifico prodotto. Tuttavia, voglio sottolineare come i concetti teorici siano sempre gli stessi ed è proprio a questi che bisogna concedere i massimi sforzi di comprensione al fine di poter, in caso di necessità, “migrare” ad una nuova soluzione software con il minimo sforzo.
E’ intuitivo pensare che, come quasi ogni oggetto che conosciamo, anche i DB prevedono una fase preliminare di creazione (a noi informatici piace molto questo aspetto “divino”) e una successiva fase operativa, di vera e propria gestione nella quale, ad esempio, preleviamo e modifichiamo specifici dati presenti nel nostro archivio.
Per ognuna di queste due fasi distinte esistono uno specifico linguaggio adatto allo scopo: DDL, ovvero Data Definition Language, con il quale costruiamo il nostro database e DML, Data Manipulation Language, con il quale gestiamo il database.
Uno dei passi chiave per modellare in maniera corretta in un archivio una certa realtà è di individuare con precisione gli oggetti caratterizzanti la realtà stessa. Pensiamo, ad esempio, di dover costruire un archivio per la gestione degli ordini per un certo negozio, piuttosto che l’elenco dei dipendenti di una data azienda per la gestione di stipendi e altro ad essi attinente. E’ evidente la necessità di individuare con precisione tali oggetti e le loro singole caratteristiche. Per la gestione degli ordini ci saranno sicuramente clienti e fornitori così come per la gestione degli stipendi individuiamo immediatamente almeno l’insieme dei dipendenti. Tali oggetti prendono il nome di entità.
Come detto queste entità hanno delle proprie caratteristiche. Nel caso dei fornitori si può pensare, a titolo di esempio, al loro numero telefonico (dovessimo contattarli per qualche reclamo), il loro recapito postale e così via. Tali caratteristiche prendono il nome di attributi. La scelta degli attributi rilevanti è un altro passo critico nella creazione di un modello efficiente della realtà che vogliamo “codificare”.
Tra tutti gli attributi di un certa entità è necessario individuarne uno (o in alcuni casi più di uno) che sia in grado di caratterizzare l’entità in modo da renderla distinguibile, senza ambiguità, dalle altre entità. Mi spiego meglio: è necessario individuare una caratteristica unica dell’entità stessa in modo che tramite questa caratteristica sia possibile riferirsi all’entità in oggetto in modo univoco. Esempio: il codice fiscale è una caratteristica che identifica in modo univoco una data persona nel senso che, banalmente, non possono esistere due persone diverse aventi lo stesso codice fiscale. Queste particolari caratteristiche prendono il nome di chiavi primarie. A tali speciali attributi ci si riferisce spesso anche con la sigla PK, acronimo appunto di Primary Key.
In linea del tutto generale, gli attributi posseggono le seguenti caratteristiche:
Il formato specifica la tipologia dell’attributo. Ad esempio, se l’attributo è di tipo testuale, numerico, data-ora, ecc. In questo ambito mi sento di dover fare alcune precisazioni. Innanzitutto vi faccio notare che, sebbene determinati attributi abbiano una loro specifica natura, è sempre il progettista del database ad effettuare la scelta del tipo di formato.
Considerate, ad esempio, il caso di un numero telefonico. A prima vista si potrebbe pensare a tale attributo come avente un formato di tipo numerico. Ad una ulteriore analisi, un po’ più attenta, si potrebbe scoprire che se trattato in tale maniera sarebbe impossibile inserire numeri come il seguente: 0824/324343456. Ovvero, indicando nel numero il separatore “/” per la parte riguardante il prefisso. Infatti, tale separatore non è una cifra ed è quindi incompatibile con tale formato numerico.
Ma, sempre in relazione ai numeri telefonici, a volte questi sono espressi in una forma del tipo: +1-310-301-5800. Nello specifico questo è il numero dello IANA, l’organismo che ha responsabilità nell’assegnazione degli indirizzi IP nella rete Internet. Il simbolo + è il segnaposto per il codice per chiamate internazionali mentre il simbolo del trattino è un modo per rendere più leggibile il numero stesso. Vi renderete conto come un tale formato sia assolutamente incompatibile con quello di un normale numero che esprime delle quantità.
Vi faccio infine un ulteriore esempio: pensiamo al caso del CAP (il Codice di Avviamento Postale). Ebbene, anche in questa situazione si potrebbe effettivamente pensare ad un campo di formato numerico. Effettivamente la scelta potrebbe risultare opportuna in caso tale attributo sia riferito a CAP italiani. Tuttavia, se volessimo utilizzarlo per inserire CAP esteri in taluni casi, per quei codici che prevedono anche la presenza di lettere, tale scelta sarebbe assolutamente errata.
La dimensione di un attributo è un’altra caratteristica critica da valutare in fase di costruzione del nostro DB. Essa rappresenta, appunto, la dimensione da riservare per un dato attribuito.
Pensiamo, a titolo di esempio, all’attributo “cognome” nella definizione di una data entità “cliente”. In buona sostanza, dobbiamo decidere quanto potrà essere lungo al massimo un generico cognome, ovvero, quanti caratteri riservare per la sua memorizzazione. La prima cosa che potrebbe venirci in mente potrebbe essere quella di non voler correre rischi scegliendo così una dimensione sicuramente abbondante. Tuttavia, 255 caratteri, che in alcuni casi rappresenta la dimensione predefinita per i campi di tipo testuale, è sicuramente una scelta sproporzionata se riferita ad un cognome. Infatti, tale scelta, se da un lato ci consentirà di inserire cognomi di lunghezza qualsiasi, d’altra parte rappresenterà, in generale, un inutile spreco di spazio. Ma come dicevano i Latini “In medio stat virtus” ovvero “la virtù sta nel mezzo”. In altre parole è buona norma mediare tali situazioni scegliendo una dimensione che risulti comunque accettabile nei casi limite. A proposito di cognomi, ad esempio, può essere sorprendente scoprire quanto possa essere lungo un cognome di origine spagnola.
L’opzionalità si riferisce al fatto che un dato attributo possa avere o meno un certo valore. Più in generale, quindi, si considera la possibilità che un dato attributo possa avere un valore nullo. Pensiamo ad esempio all’attributo “codice fiscale”, oppure “data di nascita” di un certo individuo. Se la nostra progettazione prevedesse l’obbligatorietà di tali valori non sarebbe possibile inserire nessun dato relativo ad un certo individuo di cui non si conoscesse a priori la data di nascita.
Le precedenti, mi auguro semplici, considerazioni dovrebbero essere sufficienti per farvi intendere come la scelta di una serie di parametri sia a carico del progettista e di come tali scelte possano condizionare fortemente la struttura del nostro archivio di dati. Una buona e meditata progettazione renderà il nostro DB efficace ed efficiente consentendogli una certa flessibilità per eventuali future modifiche (si parla, in gergo tecnico, di scalabilità).
Di norma si è interessati non solo alle singole entità ma anche alle associazioni che esistono tra più entità. Un esempio servirà a chiarire meglio il concetto.
Se consideriamo l’archivio dei dipendenti è naturale immaginarsi un’associazione tra l’entità dipendente e l’entità stipendio. Tali associazioni prendono in generale anche il nome di relazioni. In tale contesto i termini associazione e relazione sono sinonimi.
Un aspetto di fondamentale importanza per quanto riguarda le relazioni tra entità è la loro classificazione. E’ possibile distinguere tre tipologie fondamentali:
Vediamole allora di seguito in dettaglio:
Tale forma di relazione è la più semplice e al contempo la più scarsamente utilizzata. Essa consiste sostanzialmente nel fatto che per ciascuna entità in entrambi gli insiemi esiste esclusivamente un altro termine associato nell’altro insieme.
Un esempio potrebbe essere rappresentato da una relazione tra docenti e corsi.
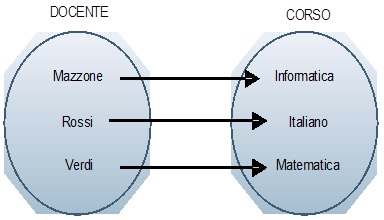
E’ ovvio, tuttavia, che l’assunzione che deve essere effettuata, per considerare la precedente come relazione uno ad uno, è che ogni docente possa tenere un solo corso e che un singolo corso sia tenuto da un solo docente. Come si po’ intuire, questo tipo di situazione non è di norma presente nella realtà a conferma della rarità di questa tipologia di relazione.
La relazione di tipo uno a molti è probabilmente la più comune. In sostanza per ogni elemento di un primo insieme esistono più elementi correlati nel secondo insieme; d’altra parte ad ogni elemento del secondo insieme può corrispondere al più un elemento del primo insieme. Un esempio classico e chiarificatore può essere quello relativo ai due insiemi, cliente e ordine, schematizzati in figura.
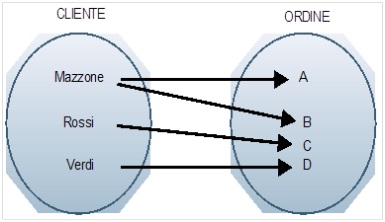
Un cliente può ovviamente effettuare vari e differenti ordini ma ogni singolo ordine corrisponde ad un unico cliente.
La relazione molti a molti prevede che ad ogni elemento di un primo insieme possano corrispondere più elementi di un secondo insieme e, viceversa, per ogni elemento del secondo insieme possono corrispondere più elementi del primo insieme.
Tale tipo di relazione, se non trattata in maniera corretta, può creare diversi problemi sia di ridondanza, ovvero inutile ripetizione, di dati che di gestione durante aggiunte ed eliminazioni di elementi.
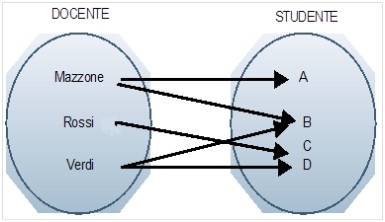
Come esempio vi porto l’associazione, visibile in figura, tra docente e studente relativamente all’attività di insegnamento. La relazione è di tipo “molti a molti” in quanto un docente insegna a differenti studenti. Inoltre, ogni studente ha più docenti.
Nel corso degli anni si sono evoluti tutta una serie di differenti modalità di organizzazione dei dati noti con il termine generico di modelli di dati. Tra questi è utile innanzitutto ricordare, ma solo per un aspetto di tipo storico, il modello reticolare ed il modello gerarchico.
Tali modelli sono stati ad un certo punto completamente soppiantati da un nuovo sistema di organizzazione dei dati noto come modello relazionale. Per diversi anni il relazionale ha costituito il modello assoluto di riferimento per la realizzazione di archivi di dati. Probabilmente, uno dei motivi dell’indiscusso successo di questo modello è stato il linguaggio che lo accompagna in maniera indissolubile noto come SQL (Structured Query Language) che vedremo nel prosieguo del nostro viaggio. Tuttavia, negli ultimi anni si è sviluppato un movimento che cerca di affiancare alle soluzioni proposte dal relazionale nuove metodologie di organizzazione dei dati motivate, tra le altre cose, dalla necessità di gestire mole di dati a dir poco enormi che oggi vengono veicolate, ad esempio, dai social network. Infatti, il modello relazionale, a causa di una serie di vincoli intrinseci mal si adatta a situazioni che prevedono la gestione di quantità di dati così grandi da essere definite cin uno specifico nome come big data. Questo movimento alternativo al relazionale prende il nome di NoSQL. Il riferimento al linguaggio SQL è dovuto, come si intuisce, al fatto che Structured Query Language è per certi apsetti considerabile quasi come se fosse un sinonimo di relazionale. Tuttavia il No si NoSQL non significa Non SQL ma più precisamente Not Only SQL, ovvero, non solo SQL a voler rimarcare il fatto che non si prevede una sostituzione assoluta del “vecchio” modello relazionale che rimane valido, se non l’unica alternativa, in diverse e differenti situazioni. Fondamentalmente, i modelli NoSQL possono essere divisi in quattro tipologie fondamentali. Una prima tipologia nota come modelli a grafo (Graph Database) e fondamentalmente altri tre modelli identificati come basato su Documenti, di tipo chiave-valore ed orientati alle colonne. In realtà, questi ultime tre modelli hanno un approccio abbastanza simile tanto da essere individuati nella loro totalità dal termine Aggregate Oriented Database. Di seguito un piccolo schema riassuntivo con relativi esempi di DBMS reali che implementano lo specifico modello.
| Database basati su grafi (Graph database) | Amazon Neptune, OrientDB |
| Database basato su Documenti (Document Database) | MongoDB |
| Database chiave-valore (Key-Value) | Redis |
| Database orientati alle colonne (Column oriented) | Cassandra, HyperBase |
Tuttavia la precedente classificazione non è esaustiva. A solo titolo di esempio un ulteriore modello di dati è rappresentato da quello noto come Object-oriented o più semplicemente modello ad oggetti. La sua peculiarità consiste nel fatto che gli oggetti di cui è composto il database contengono sia i dati sia la logica operazionale (i metodi di gestione dei dati) così come avviene nei linguaggi di programmazione che seguono il paradigma ad oggetti come il C++ o Java.
Carlo A. Mazzone
Un calcolatore elettronico è sicuramente una macchina potente e complessa. Tuttavia essa si basa su principi abbastanza elementari. L’elementarità, dovrebbe a questo punto essere intuitivo, consiste nel fatto che i segnali elettrici (stati della tensione) da esso trattati sono soltanto due.
Per semplificare al massimo le cose, si può pensare al fatto che un elemento terminale di una sua componente in un dato istante abbia corrente, oppure, su di esso, la corrente non sia presente. A questi due stati normalmente si associano per convenzione rispettivamente i valori 1 e 0. Riuscendo a gestire questi due stati (e quindi dei simboli presi da un certo alfabeto binario) associabili a questi stati e sapendo che organizzando in vario modo tali simboli possiamo rappresentare ciò che vogliamo si aprono ai nostri occhi immensi panorami.
La cosa importante da notare è che non solo possiamo rappresentare determinati valori ma possiamo su di essi realizzare tutta una serie di operazioni.
L’esempio più semplice che possiamo immaginare è quello di trasformare un segnale (simbolo) da 1 a 0 e viceversa. Tale trasformazione si riflette, sul lato strettamente fisico, nel far si che la corrente scompaia da un certo terminale e al contrario, se assente, si renda nuovamente presente. Il modulo che realizza tale funzionalità (o funzione) è noto come invertitore ed è fisicamente realizzato con un unico transistor (un elemento di base dell’elettronica). La funzione stessa è nota con il termine tecnico NOT (negazione).
Come al solito, dietro quasi ogni elemento che incontriamo si nasconde un intero e più complesso mondo; è facile, infatti, intuire che tale semplice funzione non sia l’unica. Ma, non mi stancherò mai di ripeterlo, le cose devono essere comprese nei loro aspetti e concetti più semplici e fondamentali. Così facendo le difficoltà si sciolgono come neve al sole ed il sole stesso illuminerà lo scenario complessivo mostrandocelo in tutta la sua chiarezza.
Per semplificare l’analisi della funzione svolta dall’invertitore si può fare ricorso ad una sua forma tabellare:
|
ingresso |
uscita |
|---|---|
|
0 |
1 |
|
1 |
0 |
Tale tabella prende il nome di tavola di verità della funzione NOT. Per essere precisi la funzione svolta è una funzione binaria di variabili binarie (ha a che fare con solo due possibili valori) ed è detta anche funzione commutatoriale.

La precedente discussione mi serviva per introdurre un paio di argomenti tanto importanti quanto strettamente collegati.
Da una parte abbiamo tutta una serie di potenzialità teoriche che hanno a che fare con la possibilità di gestire stati (nel nostro contesto solo due) di variabili appunto binarie e dall’altro l’implementazione pratica di tali funzionalità.
Il matematico inglese George Boole (1815-1864) sviluppò un nuovo tipo di logica che utilizzava dei simboli (logica simbolica) associati a determinate parti del discorso (inteso come ragionamento).
Tali parti di un ragionamento sono delle proposizioni che devono risultare delle affermazioni. Queste affermazioni prendono il nome di enunciati.
E’ importante sottolineare come un enunciato sia una affermazione che può risultare vera oppure falsa ma non può essere contemporaneamente sia vera che falsa. Ad esempio, una proposizione del tipo: “imparate l’informatica!” non è un enunciato (ma piuttosto un saggio invito 😉 La richiesta che un enunciato possa essere o vero o falso rientra in quello che è definito come principio del terzo escluso (ovvero esistono due sole possibilità).
“piove”, “quella matita è di colore rosso ”, “la macchina è in moto”, “10 è un numero pari”, “Benevento è una città”, ecc. sono tutti esempi di enunciati.
Boole introdusse inoltre degli operatori per mettere in relazione due affermazioni (quindi operatori binari) . Egli costruì una vera e propria algebra binaria denominata in suo onore algebra booleana (o algebra di Boole).
Boole propose quindi una nuova impostazione della logica: dopo aver rilevate le analogie fra oggetti dell’algebra e oggetti della logica, ricondusse le composizioni degli enunciati a semplici operazioni algebriche.

Nel 1938 Claude Elwood Shannon (1916-2001) ha dimostrato come l’algebra booleana potesse essere presa a fondamento per la progettazione di circuiti logici digitali, realizzando un passo fondamentale verso la concezione dei moderni computer (e questa mi sembra proprio la chiusura del cerchio). Shannon per tale eccezionale contributo è noto come il «padre del digitale».
Carlo A. Mazzone
Il termine DevOps deriva dalla fusione dei termini Development e Operations, dove il primo, development, fa riferimento alle attività di sviluppo software tipiche di un programmatore e il secondo, operations, focalizza l’attenzione su quelli che sono gli aspetti sistemistici e quindi di configurazione di macchine, di sistemi operativi e ambienti di gestione di dati. In generale, in questo contesto tali attività hanno come scopo principale quello di realizzare il cosiddetto deployment delle applicazioni ovvero quelle attività che consentono all’applicazione di essere spostate dall’ambente di produzione all’ambiente in cui l’applicazione viene create e testata all’ambiente in cui l’applicazione verrà eseguita e/o distribuita.
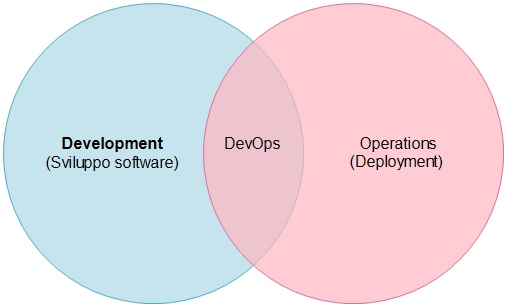
Figura – Una rappresentazione grafica del DevOps.
Il senso è che negli ultimi anni le figure di sviluppatore e sistemista, a volte in contrapposizione per impostazione lavorativa, si sono avvicinate sempre di più a causa delle evoluzioni dei sistemi, in particolare per quanto riguarda lo sviluppo in cloud e i vari ambienti di virtualizzazione. In realtà con tale contesto si fa riferimento ad un vero e proprio movimento che vede in DevOps una metodologia di gestione dei processi software che mirano all’ottimizzazione dello sviluppo di applicazioni guardando ai nuovi metodi previsti dalla programmazione Agile.
Quando si parla di sviluppo software si fa riferimento a tutto quell’insieme di attività, note anche come ciclo di vita del software, che partono dal livello di ideazione di un nuovo prodotto software e che, passando attraverso varie fasi di progettazione, sviluppo e collaudo (testing) arrivano fino al rilascio del prodotto in questione. Come si può facilmente intuire, l’insieme di queste fasi è di norma regolato da una serie di schemi standard noti come metodologie di sviluppo del software che rientrano nel più vasto contesto dell’ingegneria del software.
Potrà sembrare strano parlare di ingegneria per un prodotto non fisico ma in effetti lo sviluppo di un software viene visto come se si trattasse di un problema di tipo industriale in cui si cerca l’ottimizzazione dei processi produttivi rispetto ai tempi e ai costi degli stessi.
Ebbene, senza scendere eccessivamente nei dettagli della questione, le metodologie più vecchie (come ad esempio il modello a cascata) sono state in questi anni messe in crisi dalla velocità del mondo moderno che richiede software di qualità in tempi sempre più ristretti. DevOps, con il suo abbraccio alla metodologia Agile cerca di suggerire una possibile soluzione a tali problematiche. Già dal nome, Agile, si intuisce la volontà di sviluppare in modo dinamico. I fondatori di tale metodologia hanno stilato un vero e proprio manifesto (http://agilemanifesto.org) in cui sono elencati una serie di principi che si chiede di seguire per sviluppare software secondo questa nuova metodologia.
Di seguito un elenco tratto dal manifesto in questione:
Carlo A. Mazzone
Java affonda le proprie radici nei primi anni 90 quando la rete Internet come la conosciamo oggi era ancora solo immaginazione. Così come riportato dal sito di Oracle, azienda che ora controlla lo sviluppo di Java, nel 1991, un piccolo gruppo di ingegneri della società Sun Microsystem, chiamati il Green Team immaginarono possibile realizzare di superare le differenze presenti tra differenti dispositivi digitali e computer e per farlo iniziarono lo sviluppo un nuovo linguaggio di programmazione.
Guidato da James Gosling, il Green Team entrò nella storia dell’informatica quando nel 1995 annunciò che il più diffuso browser Internet dell’epoca, Netscape Navigator, avrebbe incorporato la nuova tecnologia Java. Da notare come proprio in questo stesso anno il nome Java viene utilizzato per la prima volta andando a sostituire il primo nome scelto, ovvero Oak, a causa di problemi di copyright relativi al fatto che tale nome era già registrato dall’azienda Oak Technologies.

Figura – James Gosling con una t-shirt con la scritta “Don’t Tell the Pope” Heretical Lecture Tour – 1632.
Come molte delle storie che hanno cambiato profondamente la società, anche la storia della nascita di Java si confonde a volte con storie che sfumano nella leggenda. Tanto per dirne una sembra che il nome Oak fosse stato scelto in riferimento ad un grande albero di quercia (oak, in lingua inglese) visibile dalla finestra degli uffici di cui lavorava Gosling presso Sand Hill Road, nella città di Menlo Park in California, eletto come luogo di ritiro per il lavoro del Green Team.
Il nome Java, invece, sembra derivi da una lunga discussione per la scelta di un nuovo nome da sostituire, come detto, al nome Oak. Alla discussione parteciparono diversi membri del Green Team e tra le varie proposte di nomi, tra cui DNA, Silk, Ruby e WRL prevalse alla fine il nome Java. Sembra che l’origine del nome sia legata al fatto che uno dei membri del team, Chris Warth, stesse bevendo una tazza di Peet’s Java mentre partecipava alla discussione relativa alla scelta del nome. Java è infatti il nome di una tipologia di caffè, così come lo è quello legato al nome “espresso”. Il nome del caffè Java in realtà deriva dal fatto che esso proviene dall’isola di Giava (Java in inglese), in Indonesia, dove fu introdotto intorno al 1600 dagli olandesi. Ovviamente questo spiega anche il motivo per cui il simbolo di Java sia legato così strettamente al caffè.
![]()
Figura – Il logo del linguaggio Java.
Sempre in tema grafico, in figura è visibile la mascotte del linguaggio di nome Duke. Dettagli sulla sua nascita sono presenti a questa URL: https://www.oracle.com/java/duke.html.

Figura – Duke, la mascotte di Java.
Per quanto riguarda l’aspetto più tecnico relativo al linguaggio, la figura mostra quelle che potrebbero essere considerate le radici di Java che, come si può osservare, derivano da una parte dallo storico linguaggio Smalltalk di fedele osservazione dei principi della programmazione orientata agli oggetti e dall’altra dal mitico linguaggio C. Il tutto passa attraverso il C++ già, anch’esso, con una spiccata declinazione verso il paradigma di programmazione ad oggetti.
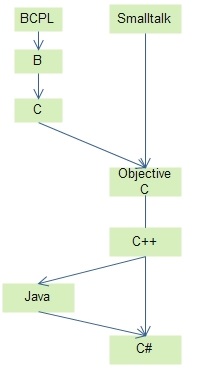
Figura – Le origini di Java.
Carlo A. Mazzone
L Italia è un paese con un gran numero di anziani e giovani, ragazze e ragazzi. Molti di loro studiano nei college come in altri paesi (Canada, USA). Molti studenti italiani studiano in America. A differenza dell Europa, gli Stati Uniti consentono l uso di alcolici a soli 21 anni, a differenza di altri paesi dell UE (tra cui lItalia). Per questo motivo, molti studenti americani acquistano documenti falsi e vanno al bar con loro. Maggiori informazioni sul blog https://my21blog.com .